
對行銷與 SEO 人來說,理解 AI 搜尋背後的 RAG(Retrieval-Augmented Generation)框架,等於拿到兩把槓桿:一把讓你的內容在檢索階段被判定為權威來源,另一把讓 AI 在生成摘要時主動附上品牌與連結。

現在的 AI 搜尋結果頁已經走向「先檢索、再生成」的雙引擎模式——Google AI Overviews、Bing、Perplexity、ChatGPT 都靠這套流程把答案塞進最顯眼的位置。
對行銷與 SEO 人來說,理解背後的 RAG(Retrieval-Augmented Generation)框架,等於拿到兩把槓桿:一把讓你的內容在檢索階段被判定為權威來源,另一把讓 AI 在生成摘要時主動附上品牌與連結。
只要同時優化「被找到」和「被引用」,就能在新一代 AI SERP 中提前卡位、引流並提升點擊率。
而 RAG 的技術,也是大幅降低 AI 幻覺的有力技術。
本文幫助無基礎的朋友也能了解 RAG(檢索增強生成)是什麼,以及 RAG 的運作流程,還有為何一般人也值得了解 RAG 的概念。
RAG 是 Retrieval-Augmented Generation,檢索增強生成。
這個中文名稱也是直接對應到 RAG 三個字:Retrieval(檢索)、Augmented(增強、增補)、Generation(生成)。
RAG 是一種 AI 架構,透過「先檢索、後生成」的流程,讓大型語言模型(LLM)在回應前,即時向外部知識庫抓取最相關的文件片段,並把這些內容連同使用者問題一起餵給模型,於是模型得以在不重新訓練的情況下產生更即時、可追溯且事實正確的答案。
RAG 是一種將「外部知識檢索」與「大型語言模型(LLM)生成」結合的架構,是一種把「搜尋」和「生成式 AI」結合起來的技術流程。
RAG 之所以「必要」,在於它用外部可更新、可控、可引用的知識,這可以補足 LLM 天生的三大弱點──有限上下文、僵硬參數記憶與幻覺。
對希望把 AI 帶入真實業務、又要求準確、合規與成本可控的組織而言,RAG 幾乎已成必備基礎設施。
而目前的語言模型為了降低幻覺,就會利用 RAG 來降低錯誤。
對多數人來說,理解 RAG 不是為了學一套很難的 AI 技術,而是為了知道,為什麼同樣都是 AI,有些回答像在瞎猜,有些卻能根據資料講得又準又可靠。簡單來說,RAG 就是讓 AI 在回答前,先去找相關資料再作答,而不是只靠它原本記住的內容直接生成答案。
這對一般使用者很重要,因為它會直接影響 AI 回答的可信度。當 AI 能先參考文件、網站、公司知識庫或你提供的資料再回答時,就比較不容易亂講,也更有機會給出貼近現況、貼近你需求的內容。
對一般人來說,懂 RAG 最大的好處,就是你會知道什麼情況下可以直接問 AI,什麼情況下應該先提供資料再問。這能幫助你在查資料、做摘要、整理文件、客服問答、內部知識查詢,甚至日常工作流程中,更有效率地把 AI 用在真正需要「根據資料回答」的地方。
RAG 是一種讓 AI 先找資料、再根據資料作答的方法,而 NotebookLM 可以看成 Google 把這套方法做成一般人也能使用的產品。
導入 RAG 的價值不在於讓 AI 更會「聊天」,而在於讓 AI 更能根據你提供的文件、網站與研究來源,有依據地回答、整理與引用資訊,而非產生資料來源外的非預期幻覺。
為了更深度理解 RAG,我們需要先更了解「Retrieval」(檢索)的概念。
在資訊檢索(Information Retrieval, IR)的語境裡,retrieval 指的是「在使用者提出查詢(query)之後,從已經建立好的索引(index)中找出最相關的文件或片段」的過程。
包括:
傳統檢索方法多採用倒排索引 + BM25 / TF-IDF。
近年則大量使用向量檢索(embedding search)、雙階段檢索 (first-stage recall → reranker) 或在 RAG(Retrieval-Augmented Generation)管線中餵給大型語言模型。
白話解釋:Retrieval=「先把可能有用的東西先翻出來」的動作──就像你先把所有可能是鑰匙的東西倒在桌上,再細看哪一把能開門。
延伸閱讀:《Retrieval(檢索)介紹:索引之後、排名之前的關鍵搜尋環節》
為了讓產生的答案更準確、資訊更豐富,「Augmented」意思是在產生文字之前,先把檢索到的知識(不管是原始段落、結構化資料,或經過前處理的摘要),轉換成適合給語言模型吸收的「增補上下文」 的過程。
包括:
常見做法:
白話解釋:Augmented=「先把找到的資料整理、加料,變成模型看得懂的便當盒」──就像你先把食材洗淨、切好、依序排進便當,再交給大廚料理。
「Generation」指的是大型語言模型(LLM)根據輸入上下文,逐 token 預測並產出最可能文字序列 的步驟,也就是 RAG 管線的最後一棒──把檢索+增強後的知識轉換成對話、摘要或文件。
包括:
常見任務:
白話解釋:Generation=「把備料好的食材烹調出道菜並擺盤」──就像是大廚根據食材特性決定火候、調味,最後端上一盤完整料理。
整體就像 先翻找→備料→烹飪 的流程:找資料(Retrieval)→ 整理加料(Augmented)→ 生成成品(Generation)。

類比成聊天版的「開書回答」
三個步驟,產生有理有據的資訊
為什麼要這麼做?
生活化例子
一句話總結
LLM 若只靠訓練參數,容易在缺乏記憶時「編故事」。RAG 先檢索可驗證片段,再讓模型生成,能大幅降低不實陳述的機率;最新系統化回顧將「降低幻覺」列為 RAG 的首要價值。業界觀察也指出,將回答「錨定」(Grounding)在真實文件,是當前最有效的幻覺緩解手段
傳統做法要把新資料「烤」進模型才能生效;RAG 只需把最新內容寫入向量索引,檢索器就能立即取用,知識鮮度與資料庫同步。這讓動態領域(新聞、金融、法規)得以在分鐘級更新。
開發成本:Fine-tune 需 GPU 訓練、監督資料與反覆調參;RAG 則多半停留在「嵌入 → 建索引」的離線流程,資源消耗小得多。
即便是 1M-token 的長上下文模型,也無法裝下整座知識庫。RAG 透過「需要時再撈」的檢索策略,把 relevant 內容壓縮到幾千 token 內,兼顧速度與完整性。
RAG pipeline 通常把檢索片段與答案一起返回,方便在 UI 直接顯示「引用 #3 來源」。這對醫療、金融、法律等高監管場景至關重要,可追溯並接受審計。
向量庫可依檔案權限隔離,檢索階段就能擋掉未授權文件;相比把機密資料烤進模型參數(難以刪除),RAG 更符合資料主權與「被遺忘權」要求。
2025 年,Google 的 AI Overviews 與每月處理超過 7.8 億次查詢的 Perplexity AI 等答案引擎,皆採用 Retrieval-Augmented Generation(RAG)技術。
出版商統計顯示,這些功能已導致 Google 自然流量普遍下降 1–25%,凸顯「能否被 RAG 檢索」決定曝光,因此我們需要理解 RAG。
RAG 透過向量語義比對擷取結構清晰、直接回答問題的段落,再生成摘要並附來源。
若品牌內容未被召回,AI 可能引用競品或過時資料,衝擊聲譽與點擊。因此,SEO 人員必須理解 RAG 的檢索邏輯、內容切塊與結構化標記策略,並持續監控 AI 層的引用,才能在新搜尋生態找到立足點。
推薦閱讀:《How generative information retrieval is reshaping search》。
以下說明 RAG 的運作及步驟,我已提供了好懂的比喻,幫助你容易理解。
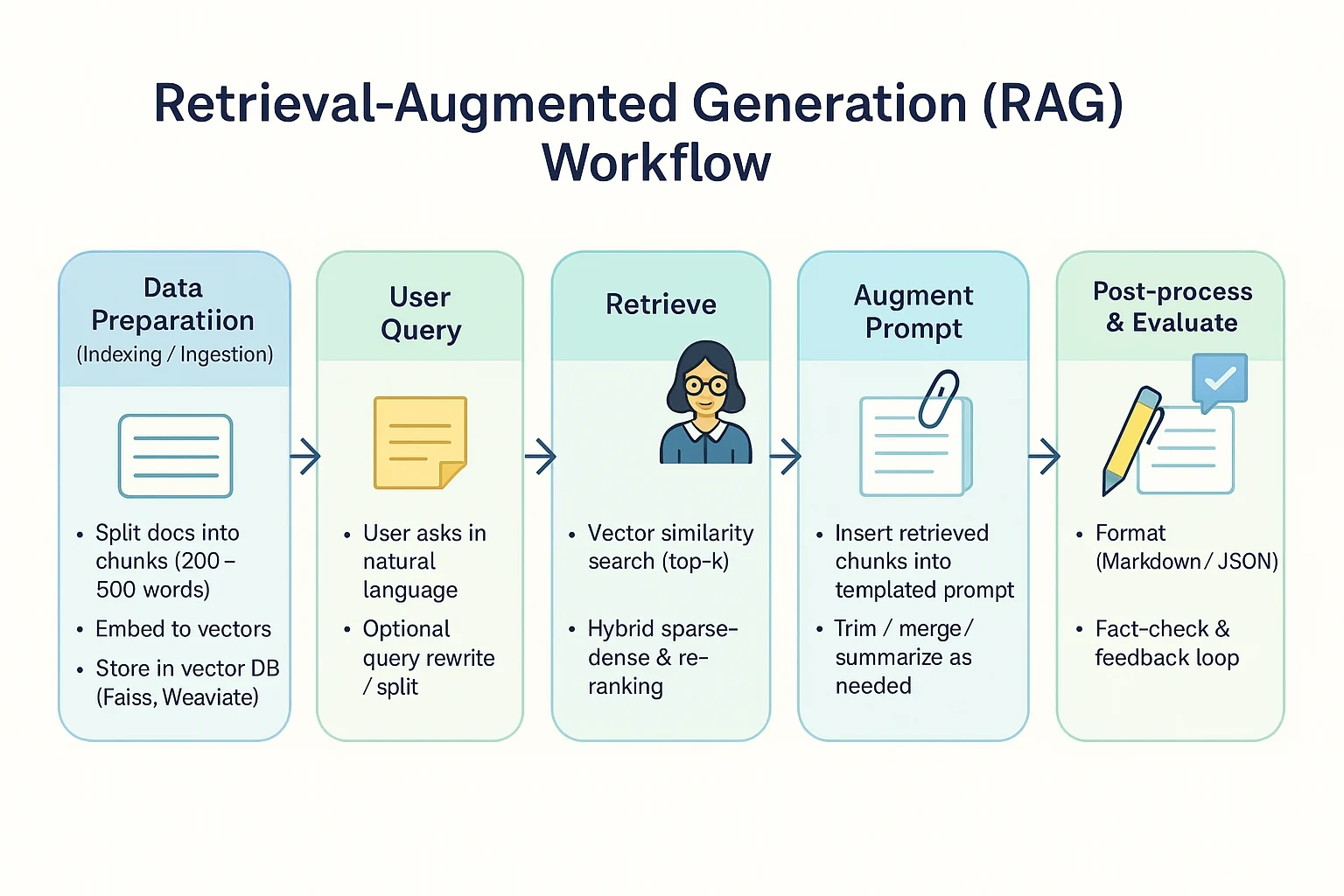
比喻:好比先把整套百科拆成「小卡片」分類,之後要找任何主題都能迅速翻到。
比喻:就像把疑問寫在便利貼交給圖書館員,請他幫忙找資料。
比喻:就像館員拿著那張便利貼在書架間穿梭,挑出最符合主題的幾頁書給你。
比喻:像把找到的重點頁影印後,用迴紋針夾在問題後面,一併遞給寫稿的專家。
比喻:好比專家看完影印資料後,用自己的話寫出一篇清楚易懂的解答稿。
比喻:就像主編最後校稿、劃重點,並附上參考書目,確保文章無誤再出刊。
在生成式搜尋(Generative Search)中,grounding(錨定、接地)指的是「把大型語言模型(LLM)的回答錨定到可驗證的資料來源,並附上引用」。
Google Vertex AI 文件明確說明:將模型輸出連結到世界知識或自有文件,可減少幻覺並提高可信度。
Microsoft、AWS 等也把 grounding 視為 Retrieval-Augmented Generation(RAG)工作流中的關鍵步驟,用外部檢索結果餵給 LLM,讓回答更準確且可追溯。
延伸閱讀:《Grounding 介紹:被 Google AI 引用的祕密,就在 Grounding 中》。
看到這裡你應該也會感覺到:感覺 Grounding 跟 RAG 很相似?
接下來我們來進一步理解這兩者的差異。
Grounding 的思考流程
RAG 的實作步驟
第 3 步實際上就替模型「鋪好」了 grounding data。
用 RAG 不代表一定沒有幻覺;檢索到的片段可能不準確,或 prompt 太長被截斷,仍需額外的「真實性檢查」。
Grounding 不一定得靠 RAG:
Fine-tune ≠ Grounding:微調把知識寫進模型權重;Grounding / RAG 則是用「外部記憶」補充最新或私有資訊。
隨著 AI 搜尋的發展,我們希望出現在各個 AI 搜尋引擎、各個垂直的搜尋引擎。
在 AXO(AI eXperience Optimization)中,我根據不同的層次,分類了 AAO、BEO、GEO、AEO、SEO,定義了不同的工作任務。
SEO 找得到 → AEO 說得到 → GEO 連得到 → BEO 買得到 → AAO AI 替你做到。
延伸閱讀:《AXO(AI 全搜尋體驗)介紹:一次理解搜尋的未來與布局》

RAG(Retrieval-Augmented Generation)把資訊檢索與大型語言模型黏在一起:先到文件庫抓出與問題相符的片段,再讓模型依據這些片段即時完成回答。RAG 像給 LLM 插上「即插即用的外部記憶」,因此面對從未見過的新政策或內部專用文件,也能說出有根據的答案,同時還能顯示來源方便核對。
真正需要「訓練」的是檢索管線而非大模型:先把原始文件清洗、切塊、向量化並存入向量資料庫,再用對比學習或強化學習去微調檢索器,讓它更懂得抓重點。生成模型通常只做輕量微調(如 LoRA)或甚至零微調就能上陣,只要整體流程持續評測、回饋、更新索引,就算新文件天天進來也不怕。
RAG 的首要任務是把「最新或私有知識」即時灌入回答,避免模型卡在舊資料庫裡。透過附帶引用段落,RAG 同時降低幻覺、提高可追溯性,讓使用者一眼就能驗證真偽。結果是知識覆蓋面更廣、答案更可靠,特別適合法務、金融、技術支援等必須講求正確性的場景。
相較動輒百億參數的全面微調,RAG 只要維護檢索管線,就能用較小的計算量跟成本獲得「新、準、可查」的回應。私有文件停留在檢索階段,不進大模型權重,既符合企業資料治理也方便快速下線或更新。當你需要即時知識又在意隱私與成本,RAG 往往是效率最高、風險最低的選擇。
很多人會把 RAG 和 LLM 混在一起,但兩者其實不是同一個概念。LLM 是負責理解語言、生成文字與回答問題的核心模型,主要依靠訓練過程中學到的知識來作答;而 RAG 則是一種讓 LLM 在回答之前,先去查找外部資料,再根據找到的內容生成答案的方法。
簡單來說,LLM 像是 AI 的大腦,RAG 則像是幫這個大腦接上一個可即時查資料的開卷系統,因此特別適合需要依據文件、知識庫或最新資訊來回答的情境。



